
Projects
Active Projects
Adobe Experience Platform I’m driving the applied R&D for AI Assistant in Adobe Experience Platform and its underlying GenAI platform. We are bringing the power of Generative AI and Knowledge Graph to enterprise systems where accuracy, privacy, trust, governance and extensibility are non-negotiable. Our work will transform the way companies approach audiences, journeys and personalization at scale.
News Coverage:
- 06/18/2024 - Bloomberg Tech Disruptors: link
Active Projects @Apple that I perviously led:
Apple Knowlege Platform: I led the building of the next-generation of machine learning solutions in the Knowledge Platform at Apple and help power features including Siri and Spotlight. The technology we built is redefining how billion of people use their computers and mobile devices to search and find what they are looking for. In particular, I led the efforts on growing and serving open domain knowledge graph and drove a new agenda on LLM+KG. More details about some of the work can be found here. |
Active Projects @IBM Research that I perviously started and led:
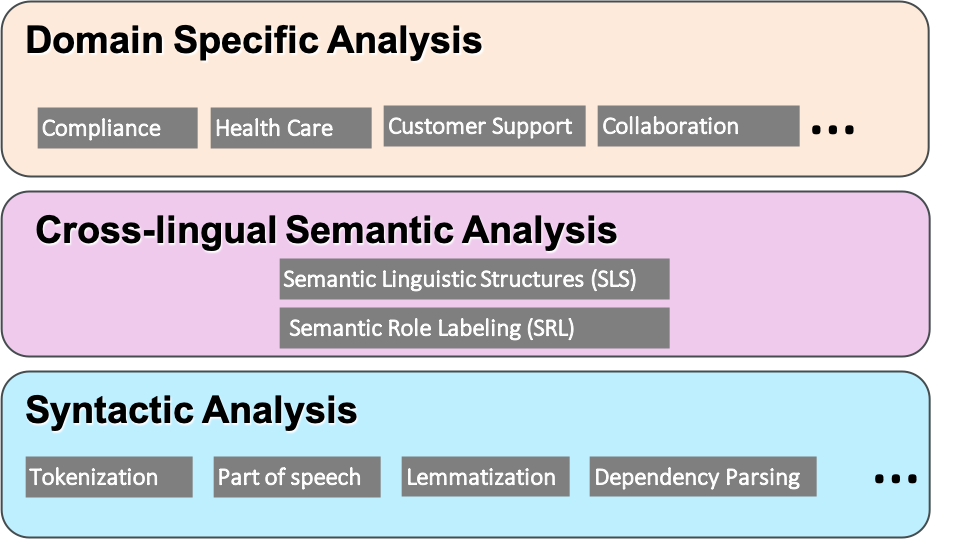 | Universal Proposition Banks Universal Proposition Banks builds on the Universal Dependencies project and adds a layer of crosslingually unified shallow semantic information. It enable the training of crosslingual parsers and the study of crosslingual semantics. The key idea is to generate high quality prosition banks at scale with a combination of auto-generation and human-in-the-loop methods. In addition, we also study shallow semantic parsing models for better quality, runtime performance, and maintainability as well as the building of novel NLP applications on top of such crosslingual unified shallow semantic information. Business Impact: (1) Foundation for Expanded Shallow Semantic Parsing (ESSP), a major differientiating advanced NLP primitive in Watson NLP, an embedding NLP library used widely within IBM products and solutions; (2) Powers multiple IBM products and solutions such as Watson Discovery and Watson AIOps. Scientific Impact: (1) Public dataset; (2) Multiple research papers on data generation, curation, model building at top NLP conferences; (3) More to come in the near future. |
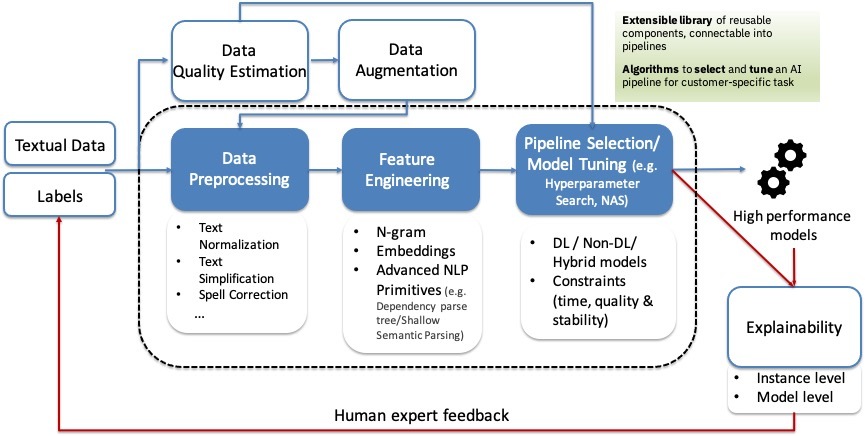 | AutoAI for Text AutoAI for Text is a framework that provides both the components and the tools that facilitate the process of NLP model development for text data, via automation, ease-of-use and explainability. We target users at different levels of skills or expertise, with a particular focus on 1) data scientists who want to quickly get a head start in their text processing projects, and 2) advanced model developers who will want to optimize and fine-tune their models before deployed in production. The goal of AutoAI for Text is to make such users more efficient by reducing model development time and effort while at the same time improving the quality of their models through the use of automatic optimization.Business Impact: (1) Currently used by internal NLP teams to scale model development; (2) Key differentiating technology resulting in major customer engagements as an Early Research Offering; (3) In the process to transfer to multiple IBM products. Scientific Impact: Demos and publications. |
 | Deep Document Understanding PDF understanding is a general AI problem. In this project, we aim to provide an out-of-box solution to programmatically process PDF documents into a common target representation (e.g., HTML with extensions) for downstreaming applications. The main research challenges are (1) maintain formatting, reading order & structural metadata (e.g. lists, headings, font) and (2) capture non-textual content (e.g. tabular content).Business Impact: (1) Foundation of Watson OneConversion, an innner project for document conversion; (2) Powering multiple IBM products and solutions. Scientific Impact: Workshops, demos, tutorials and publications. |
Matured Projects
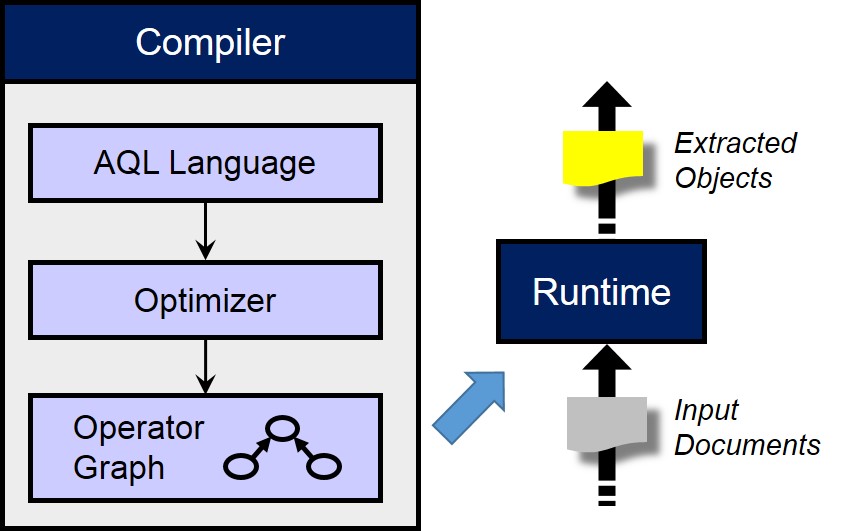 |
SystemT, a declarative text understanding system for the enterprise, has been designed and developed to address pressing requirements to powering AI applications for business. It is based on the basic principle underlying relational database technology: complete separation of specification from execution. SystemT uses a declarative rule language, AQL, and an optimizer that generates high-performance algebraic execution plans for AQL algorithms. It makes text understanding orders of magnitude more scalable and easier to use, maintain and customize. Business Impact: It is embedded in over 20 commercial product offerings and used in numerous internal and external projects. Research Impact: Various aspects of SystemT have been published in over 50 major research conferences and journals in diverse areas: from natural language processing, database systems, and human-computer interaction. |
Completed Projects
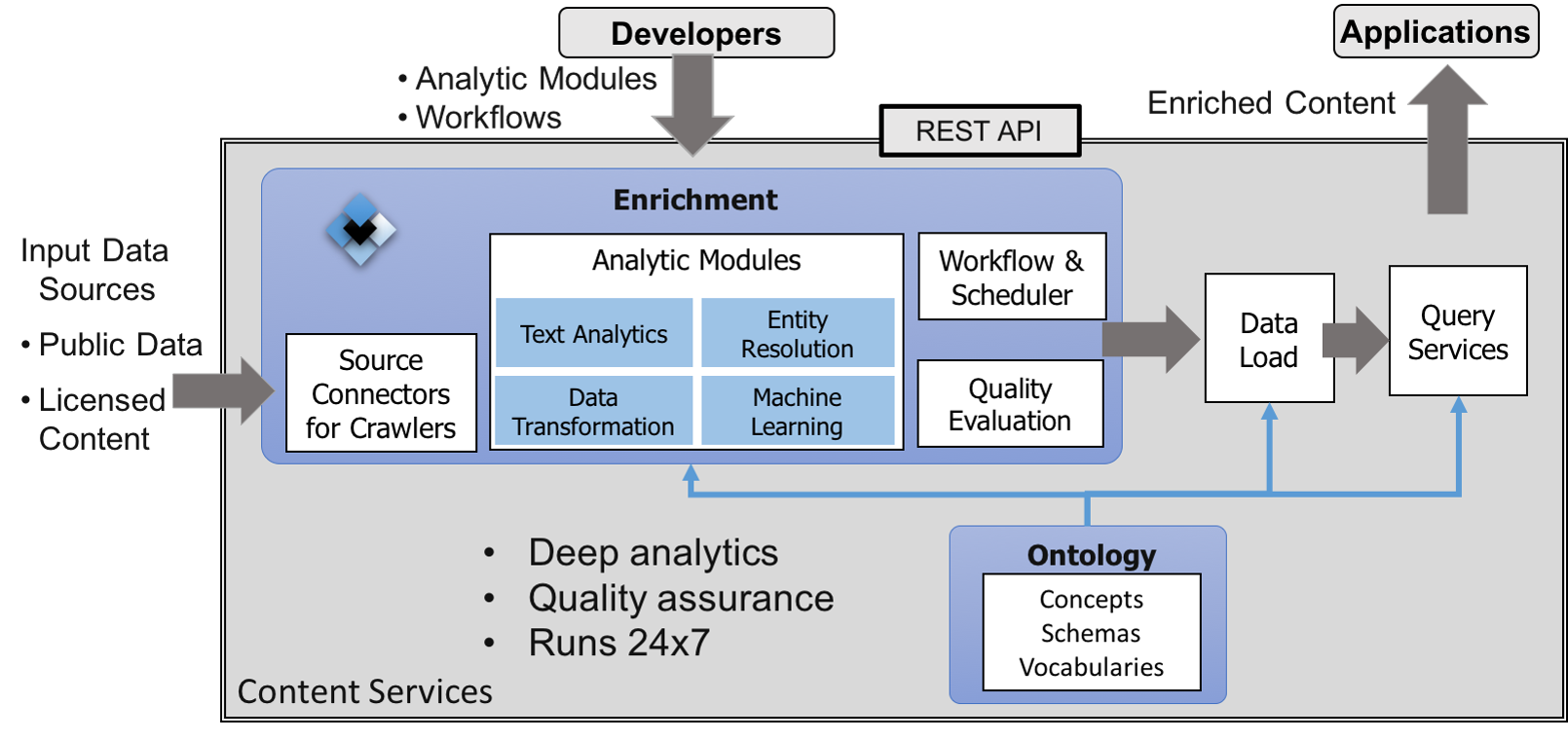 | Content Services: Building Large-Scale Domain-Specific Knowledge Base The Content Services system provides the ability to create and interact with large-scale domain- specific knowledge bases by analyzing and integrating multiple (un/semi)structured content sources. Such a capability is the foundation for many industry-focused cognitive systems. This project built a scalable platform the addresses the challenges of (1) how to represent and incorporate domain knowledge; (2) how to enable a robust platform-agnostic workflow for knowledge extrac- tion and integration from different data sources in different formats in both batch and incremental fashion; (3) how to monitor and maintain data quality; (4) how to store and query the KB to support a wide-spectrum of use cases.Business Impact: (1) Production-ready platform for building Large-Scale domain-specific knowledge base with several major components resused in multiple products and services. (2) A large-scale financial content knowledge base for all public companies and banks in US constructed from over 20 years' SEC and FFIEC financial fiings with multiple customer engagements. Scientific Impact: Varies aspects of the Content Services system are covered in multiple research papers, leading to follow up research projects on table extraction & understanding, table QA, OQL and natural language query to databases. |
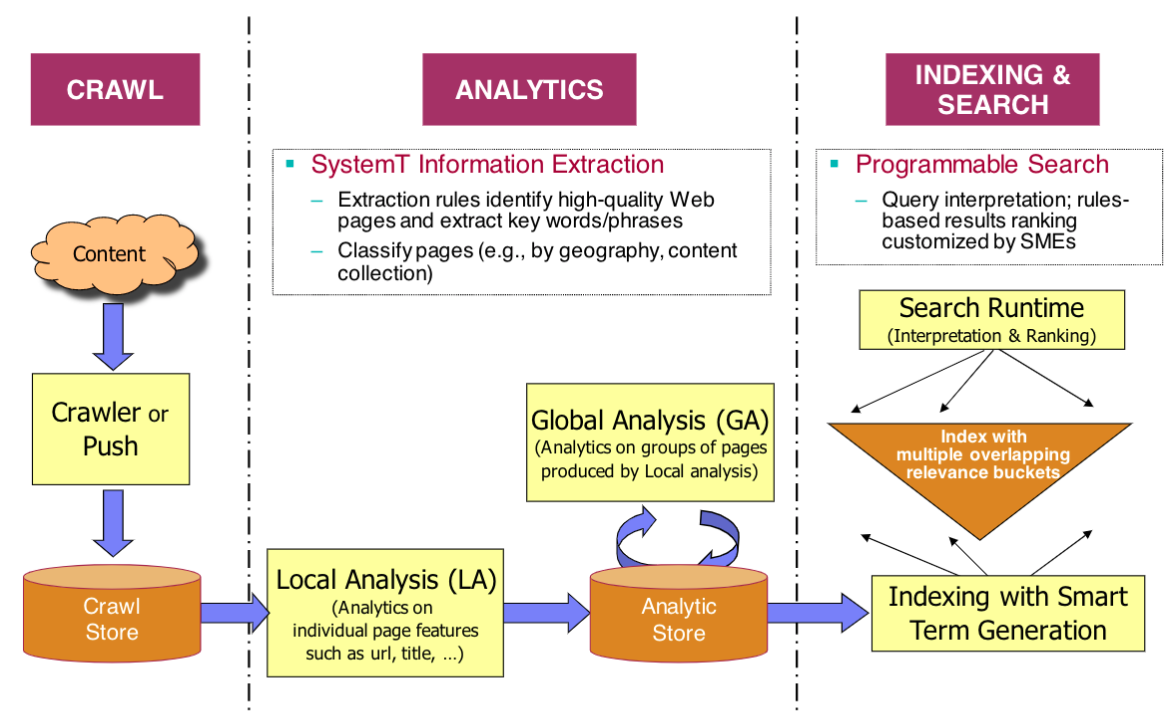 | Gumshoe: Programmable Search for the Enterprise Gumshoe was a scalable and highly customizable enterprise search solution and successfully deployed the solution within the IBM enterprise to power both extranet (ibm.com) and intranet (w3) search. The Gumshoe architecture marries sophisticated backend content analytics workflow with a unique programmable runtime search architecture specifically designed to provide flexible and powerful search quality management.Business Impact: In production from 2011 to 2017, culminating in the highest ever search satisfaction scores in the history of the CIO WorkPlace Effectiveness Survey during its active deployment. Scientific Impact: Pineered the notion of a "programmable search architecture" that permits both transparency as well as maintainability and debugability. |